Data Organization¶
The Data Portal is organized in a hierarchical structure. We welcome contributions to the Portal. Use this form to express interest in adding your data to the Portal.
Overview¶
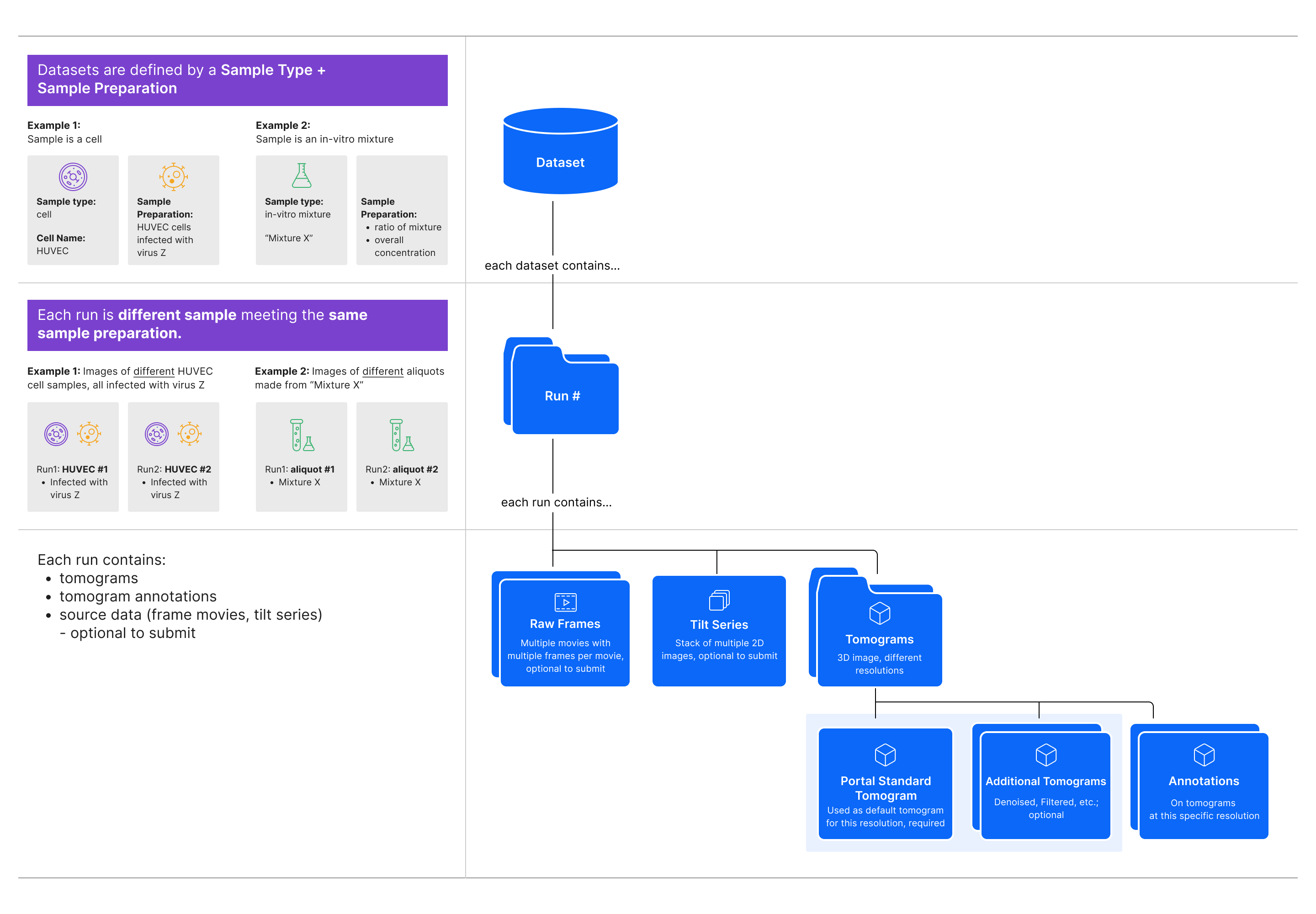
CryoET Data Portal Data Hierarchy¶
As shown in the diagram above, the CryoET Data Portal has 3 levels in the data hierarchy:
Dataset is a set of image files for tilt series, reconstructed tomograms, and cellular and/or subcellular annotation files. Every dataset contains only one sample type prepared with the same conditions. The dataset title, such as “S. pombe cryo-FIB lamellae acquired with defocus-only,” summarizes these conditions. Samples can be a cell, tissue or organism; intact organelle; in-vitro mixture of macromolecules or their complex; or in-silico synthetic data, where the experimental conditions are kept constant. Datasets typically contain multiple runs (see below). Downloading a dataset downloads all files, including all available tilt series, tomograms, and annotations.
Run is one experiment, or replicate, within a dataset, where all runs in a dataset have the same sample conditions. Every run contains a collection of all tomography data and annotations related to imaging one physical location in a sample, and within one dataset, runs may correspond to individual locations within a single sample. Each run typically contains one tilt series and all associated data (e.g. movie frames, tilt series image stack, tomograms, annotations, and metadata), but in some cases, it may be a set of tilt series that form a mosaic. Runs contain at least one annotation for every tomogram. When downloading a run from a Portal page, you may choose to download the tomogram or all available annotations. To download all data associated with a run (i.e. all available movie frames, tilt series image stack, tomograms, annotations, and associated metadata), use the API.
Annotation is a point or segmentation indicating the location of a macromolecular complex in the tomogram. On a run overview page, you may choose to download individual annotations.
All data is added to the Portal through Depositions, which is described below, and a subset of depositions are displayed in the depositions tab on “Browse Data” page of the Portal.
For more detailed explanations of all data types in the Portal refer to the sections below.
Depositions¶
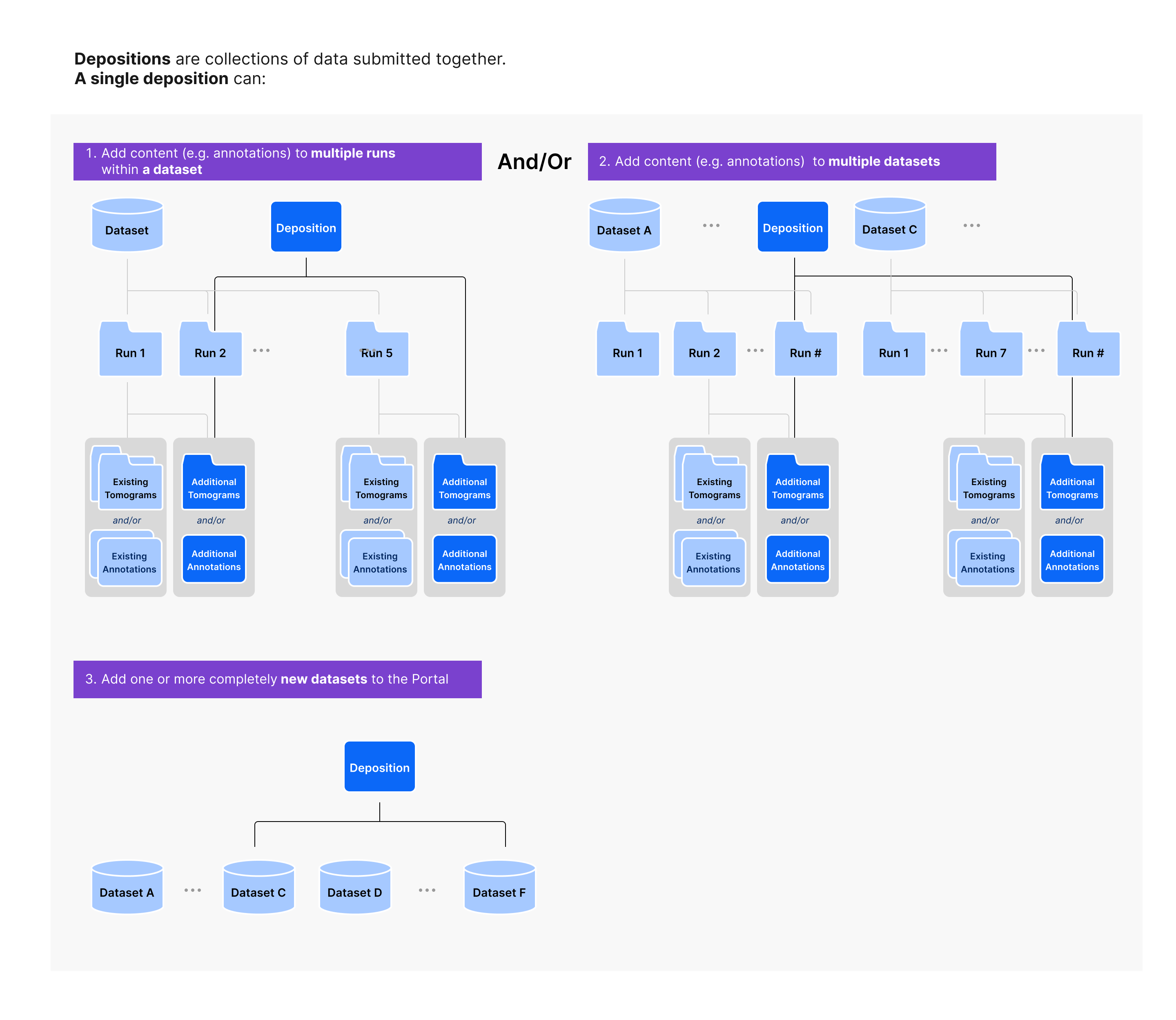
Types of depositions¶
Depositions are collections of data submitted together. All data being submitted together will be tagged with the same deposition ID, starting with CZCDP (e.g. CZCDP-12345; note that only the numeric part is supported in the API). On the Portal, we will surface depositions that contain annotations submitted together. In the future, depositions surfaced on the Portal may include tomograms added to existing datasets or sets of datasets contributed together.
Datasets¶
Datasets are contributed sets of image files associated with imaging one sample type with the same sample preparation methods. Datasets contain runs, where each run corresponds to imaging one physical location in the prepared samples. Dataset IDs start with DS (e.g. DS-10000; note that only the numeric part is supported in the API).
The Browse Datasets page shows a table of all datasets on the Portal. These datasets are not currently ordered. Instead, the left side filter panel provides options for filtering the table according to files included in the datasets, such as ground truth annotation files; the author or ID of the dataset; organism in the sample; hardware; metadata for the tilt series or reconstructed tomograms. In addition, the search bar filters based on keywords or phrases contained in the dataset titles. The dataset entries in the table have descriptive names, such as “S. pombe cryo-FIB lamellae acquired with defocus-only,” which aim to summarize the experiment as well as a Dataset ID assigned by the Portal, the organism name, number of runs in the dataset, and list of annotated objects, such as membrane. Datasets on the Portal may be found in other image databases. On the Browse Datasets page, the datasets table shows the EMPIAR ID for datasets that are also found on the Electron Microscopy Public Image Archive.
On a given Dataset Overview page, the View All Info panel contains metadata for the dataset. These metadata are defined in the tables below including their mapping to attributes in the Portal API:
Dataset Metadata
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Deposition Date |
|
Date when a dataset is initially received by the Data Portal. |
Grant ID |
|
Grant identifier provided by the funding agency. |
Funding Agency |
|
Name of the funding agency. |
Related Databases |
|
The dataset identifier for other databases, e.g. EMPIAR, that contain this dataset. |
Sample and Experiment Conditions
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Sample Type |
|
Type of sample: cell, tissue, organism, intact organelle, in-vitro mixture, in-silico synthetic data, other. |
Organism Name |
|
Name of the organism from which the biological sample is derived from, e.g. homo sapiens. |
Tissue Name |
|
Name of the tissue from which a biological sample used in a CryoET study is derived from. |
Cell Name |
|
Name of the cell from which a biological sample used in a CryoET study is derived from, e.g. sperm. |
Cell Line or Strain Name |
|
Cell line or strain for the sample e.g. C57BI |
Cellular Component |
|
Name of the cellular component, e.g. sperm flagellum |
Sample Preparation |
|
Description of how the sample was prepared. |
Grid Preparation |
|
Description of how the CryoET grid was prepared. |
Other Setup |
|
Description of other setup not covered by sample preparation or grid preparation that may make this dataset unique in the same publication. |
Tilt Series
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Acceleration Voltage |
|
Electron Microscope Accelerator voltage in volts. |
Spherical Aberration Constant |
|
Spherical Aberration Constant of the objective lens in millimeters. |
Microscope Manufacturer |
|
Name of the microscope manufacturer. |
Microscope Model |
|
Microscope model name. |
Energy Filter |
|
Energy filter setup used. |
Phase Plate |
|
Phase plate configuration. |
Image Corrector |
|
Image corrector setup. |
Additional microscope optical setup |
|
Other microscope optical setup information, in addition to energy filter, phase plate and image corrector. |
Camera Manufacturer |
|
Name of the camera manufacturer. |
Camera Model |
|
Camera model name. |
Dataset Overview Page¶
The table on a Dataset Overview page contains an overview of the runs in the dataset. Each run has a name defined by the dataset authors as well as a Run ID, which is assigned by the Portal and is subject to change in the rare case where the run data needs to be re-ingested to the Portal. In addition to the run name, the tilt series quality and list of annotated objects is detailed for each run. Each entry has a View Tomogram button which will display the tomogram using an instance of Neuroglancer in the browser. The tomogram is visualized along with annotations that are manually chosen to display as many annotations as possible without overlap or occlusion.
Dataset Download Options¶
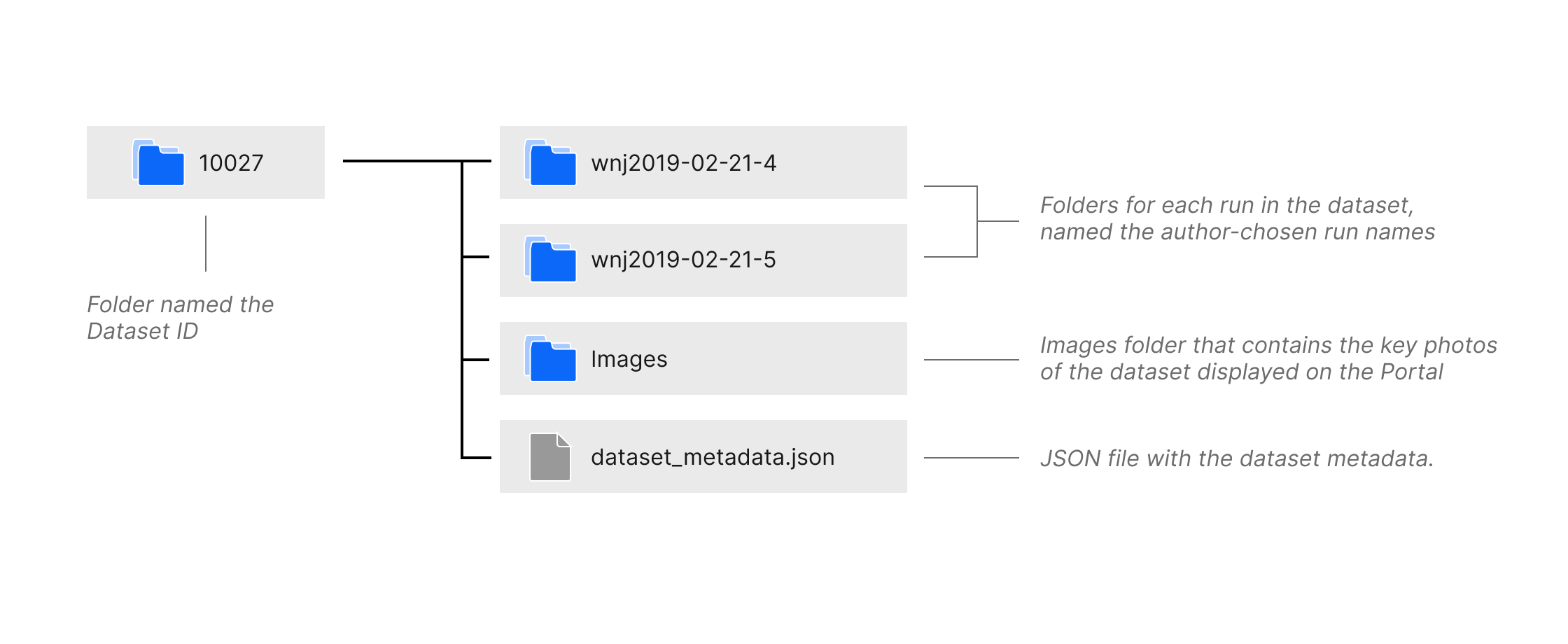
File Structure of a downloaded dataset¶
The Download Dataset button opens a dialog with instructions for downloading the dataset using Amazon Web Services Command Line Interface or the Portal API. Datasets are downloaded as folders named the Dataset ID. As shown in the diagram above, the folder contains subfolders for each run named the author-chosen run name, a folder named Images which contains the key photos of the dataset displayed on the Portal, and a JSON file named dataset_metadata.json containing the dataset metadata. The run folders contain subfolders named Tomogram and TiltSeries, containing the tomogram and tilt series image files, and a JSON file named run_metadata.json containing the run metadata. More details on the run folder file structure is found in the documentation below.
The metadata schema of any JSON file stored with the data on the data portal’s S3 bucket is described in LinkML and can be found here.
Runs¶
A tomography run is a collection of all data and annotations related to one physical location in a sample and is associated with a dataset that typically contains many other runs. On the Data Portal pages, runs are directly linked to their tomograms. For a single run, multiple tomograms of different spacings can be available. Run IDs start with RN (e.g. RN-427; note that only the numeric part is supported in the API).
An overview of all runs in a dataset is presented in the Dataset Overview page. Each run has its own Run Overview Page, where the View All Info panel contains metadata for the run. These metadata are defined in the tables below including their mapping to attributes in the Portal API:
Tilt Series
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Tilt Series ID |
|
Numeric identifier. |
Microscope Manufacturer |
|
Name of the microscope manufacturer. |
Microscope Model |
|
Microscope model name. |
Phase Plate |
|
Phase plate configuration. |
Image Corrector |
|
Image corrector setup. |
Additional microscope optical setup |
|
Other microscope optical setup information, in addition to energy filter, phase plate and image corrector. |
Acceleration Voltage |
|
Electron Microscope Accelerator voltage in volts. |
Spherical Aberration Constant |
|
Spherical Aberration Constant of the objective lens in millimeters. |
Camera Manufacturer |
|
Name of the camera manufacturer. |
Camera Model |
|
Camera model name. |
Energy Filter |
|
Energy filter setup used. |
Data Acquisition Software |
|
Software used to collect data. |
Pixel Spacing |
|
Pixel spacing for the tilt series. |
Tilt Axis |
|
Rotation angle in degrees. |
Tilt Range |
|
Total tilt range in degrees. |
Tilt Step |
|
Tilt step in degrees. |
Tilting Scheme |
|
The order of stage tilting during acquisition of the data. |
Total Flux |
|
Number of electrons reaching the specimen in a square Angstrom area for the entire tilt series. |
Binning from Frames |
|
Describes the binning factor from frames to tilt series file. |
Series is Aligned |
– |
True or false, indicating whether the tilt series images have been transformed to account for the tomographic alignment. |
Related EMPIAR Entry |
|
EMPIAR dataset identifier If a tilt series is deposited into EMPIAR. |
Tomograms Summary
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Total Tomograms |
|
Number of tomograms in this run. |
Samplings Available |
||
Tomogram Processing |
see how to get all types of post-processing methods for tomograms in this run |
|
Annotated Objects |
Run Overview Page¶
The summary on the Run Overview page shows a subset of the run metadata as well as the number and type of files in the run and the tilt series quality score. The View Tomogram button opens the associated tomogram along with annotations using an instance of Neuroglancer in the browser. The annotations displayed with the tomogram are manually chosen to display as many annotations as possible without overlap or occlusion.
The table on a Run Overview page contains an overview of the annotations for the tomograms in this run. Each annotation has an Annotation ID, which is assigned by the Portal and is subject to change in the rare case where the annotation data needs to be re-ingested in the Portal. In addition to the Annotation ID, the table shows the object annotated, the type of the annotation, such as segmentation or point, the method used for annotation, such as manual or automated, and metrics for assessing the annotation.
Run Download Options¶
The Download ... button on the Run Overview page opens a dialog for downloading tomograms or instructions for downloading all annotations or all run data. Individual tomograms can be downloaded directly in the browser as MRC or OME-Zarr files following selection of which tomogram to download based on the tomogram sampling and processing. The All Annotations option provides instructions on using Amazon Web Services Command Line Interface or the Portal API to download.
You can also use the Portal API to download all run data as a folder using the Run ID in the download dialog or in the header on the Run Overview page. For example, to download all run data for Run ID 645 into your current working directory, use the below code snippet:
from cryoet_data_portal import Client, Run
client = Client()
run = Run.get_by_id(client, 645)
run.download_everything()
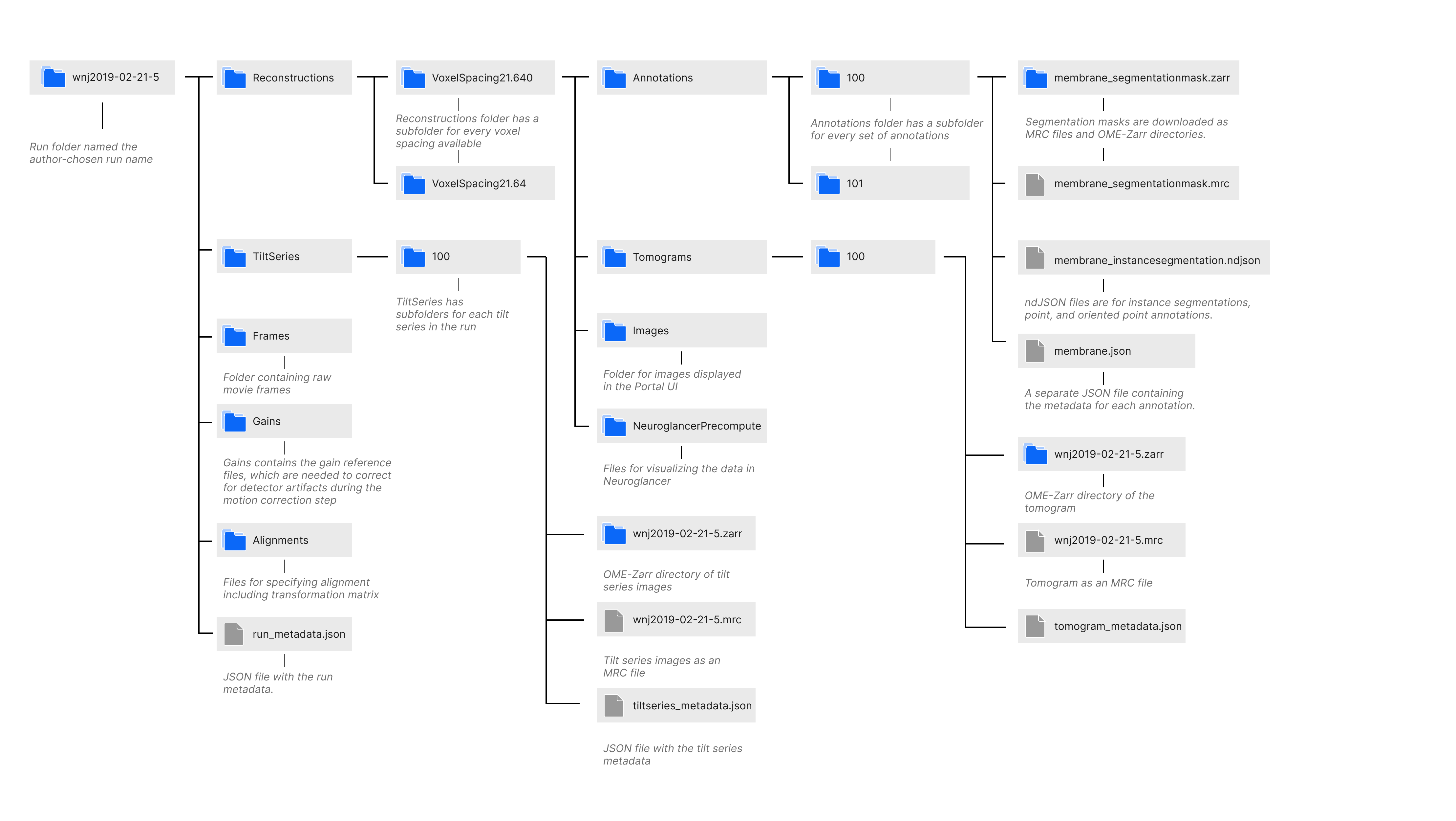
Runs are downloaded as folders named the author-chosen run name. As shown in the diagram above, the folder contains subfolders named Alignments, Frames, Gains, Reconstructions, and TiltSeries; and a JSON file named run_metadata.json containing the run metadata. The Alignments folder contains a JSON file for every alignment that specifies the alignment parameters including the affine transformation matrix. The Frames and Gains folders contain the raw movie frames and the gain files for correcting for the detector’s sensitivity, respectively. The TiltSeries folder contains the tilt series images as an MRC file and OME-Zarr directory as well as a JSON file with the tilt series metadata. The Reconstructions folder has a subfolder for every voxel spacing available, and each of those folders contains subfolders NeuorglancerPrecompute, which has files for visualizing the data in Neuroglancer; Images, which contains the key photos of the run displayed on the Portal; Tomograms, which has the tomograms associated with the run as an MRC file and OME-Zarr directory along with tomogram metadata and metadata for visualizing the tomogram with Neuroglancer; and Annotations. More details on the Annotation folder file structure is found in the documentation below.
Tilt Series¶
Please refer to our educational article about CryoET Data Collection for a detailed description of tilt series. Each tilt series has a Tilt Series ID, which is assigned by the Portal and is subject to change in the rare case where the tilt series data needs to be re-ingested in the Portal. Tilt Series IDs start with TS (e.g. TS-12345; note that only the numeric part is supported in the API).
Frames¶
When acquiring tilted projections of a sample as part of a CryoET tilt series acquisition, one actually acquires a movie at each tilt (stored as so-called “movie stacks” or “frame stacks”) so that beam induced motion can be corrected after acquisition by compensating translations and warping. Upon correction, these frames are summed to form a single image at each tilt angle, and the collection of images is referred to as the tilt series. Usually, each run of a CryoET dataset will have 30-50 frame stacks of 5-100 frames associated with it, where the number of stacks is the same as the number of tilts during acquisition. Acquisition metadata are stored in MDOC-files, which are text-based with one section per frame stack.
When available, the Frames folder in a downloaded run contains the raw frame images, acquisition metadata MDOC file, and an additional metadata file in JSON format.
Gains¶
Individual pixels or whole sectors of the direct electron detector used in CryoET Data Acquisition can have different responses to the same incident signal. In order to control for this uneven detector response, an image is acquired without any sample in the beam path. This flat-field image, called a “gain reference”, allows correction of the recorded signal in the images acquired of a real sample. A single gain reference can be applicable to multiple runs of a cryoET dataset.
When available, the Gains folder in a downloaded run contains the gain reference image.
Tilt Series Assembly¶
The raw frame stacks from image acquisition are motion corrected and averaged at each tilt angle to form the tilt series. Please refer to our educational article about CryoET Data Collection for a detailed description of tilt series assembly from the raw frame stacks.
When available, the TiltSeries folder in a downloaded run contains the tilt series images in MRC and OME-Zarr file format, tilt series metadata JSON file, and the rawtlt file. The rawtlt file contains a list of the tilt angles from image acquisition and is used by downstream programs for alignment and tomogram reconstruction.
Tilt Series Quality¶
The tilt series quality score is found on Dataset Overview pages in the run table and on Run Overview pages in the header. This score is assigned by the dataset authors to communicate their quality estimate to users. This score is only applicable for comparing tilt series within a dataset on a relative subjective scale. Score ranges 1-5, with 5 being best. Below is an example scale based mainly on alignability and usefulness for the intended analysis.
Rating |
Quality |
Description |
|---|---|---|
5 |
Excellent |
Full Tilt Series/Reconstructions could be used in publication ready figures. |
4 |
Good |
Full Tilt Series/Reconstructions are useful for analysis (subtomogram averaging, segmentation). |
3 |
Medium |
Minor parts of the tilt series (projection images) need to be or have been discarded prior to reconstruction and analysis. |
2 |
Marginal |
Major parts of the tilt series (projection images) need to be or have been discarded prior to reconstruction and analysis. Useful for analysis only after heavy manual intervention. |
1 |
Low |
Not useful for analysis with current tools (not alignable), useful as a test case for problematic data only. |
Tomograms¶
Please refer to our educational article about CryoET Data Processing for a high level description of how tomograms are reconstructed from tilt series. Part of the tomogram reconstruction process, involves aligning the tilt series and correcting it using an estimated contrast transfer function (CTF). A detailed article on this process is coming soon. On the Portal, alignnment metadata JSON files are available for every tomogram, and these files contain the affine transformation matrix along with information such as the alignment type (e.g. local vs global).
Tomograms are summarized in a table on Run Overview pages. Note that by default the Annotations table is displayed on the Run Overview pages, but you can toggle to the Tomograms table by clicking the tab above the table. Each tomogram has a Tomogram ID, which is assigned by the Portal and is subject to change in the rare case where the tomogram data needs to be re-ingested in the Portal. Tomogram IDs start with TM (e.g. TM-6091; note that only the numeric part is supported in the API).
The Tomogram table has columns with the author-chosen Tomogram Name (including the Tomogram ID and a truncated list of authors), Deposition Date, Alignment ID (ID of the alignment file used to align the tilt series for tomogram reconstruction), Voxel Spacing (containing both the voxel spacing in angstroms and the size of the tomogram in pixels), Reconstruction Method (e.g. WBP for weighted back projection), and Post-Processing information (e.g. denoised, filtered, etc.).
When available, each tomogram in the table has its own View Tomogram button which will open Neuroglancer in a new tab with the tomogram along with all its available annotations preloaded. Check out our Neuroglancer Quickstart to learn more about navigating Neuroglancer.
Each tomogram entry in the table also has a Download button which opens a dialog containing direct download and code snippets for other download methods.
Each tomogram has its own metadata, which can be viewed using the info icon on the entry in the tomograms table. These metadata are defined in the tables below including their mapping to attributes in the Portal API:
Tomogram Overview
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Authors |
|
The tomogram authors of this tomogram. |
Publications |
|
Comma-separated list of DOIs for publications associated with the tomogram. |
Related Databases |
|
Comma-separated list of other database identifiers (e.g. EMPIAR-11445) if the tomogram is also deposited into other databases. |
Deposition Name |
|
The name of the deposition this tomogram is a part of. |
Deposition ID |
|
The ID of the deposition this tomogram is a part of. |
Deposition Date |
|
Date when a tomogram is initially received by the Data Portal. |
Release Date |
|
Date when a tomogram is made public by the Data Portal. |
Last Modified Date |
|
Date when a tomogram was last modified in the Data Portal. |
Reconstruction and Processing
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Is Portal Standard |
|
Whether this tomogram is a standardized reconstruction of the original tomogram, following a consistent format and coordinate space, and completed by CZII. |
Submitted by Dataset Author |
|
Whether this tomogram was submitted by the author of the dataset it belongs to. |
Reconstruction Software |
|
Name of software used for reconstruction |
Reconstruction Method |
|
Describe reconstruction method (WBP, SART, SIRT). |
Processing Software |
|
Processing software used to derive the tomogram. |
Processing |
|
Describe additional processing used to derive the tomogram |
Voxel Spacing |
|
Voxel spacing equal in all three axes in angstroms |
Size (x,y,z) |
|
Comma separated x,y,z dimensions of the unscaled tomogram in pixels. |
Fiducial Alignment Status |
|
Fiducial Alignment status: True = aligned with fiducial False = aligned without fiducial. |
Ctf Corrected |
|
Whether this tomogram is CTF corrected |
Alignment
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Alignment ID |
|
The ID of the alignment used to generate this tomogram. |
Is Portal Standard. |
|
Whether or not the tomogram is considered canonical, meaning as minimal processing as possible. |
Alignment Type |
|
Method of alignment used to generate the tomogram (e.g. local, global, fiducial-based, etc.) |
Dimension (x,y,z) |
|
Comma separated x,y,z dimensions of the unscaled tomogram in angstroms. |
Offset (x,y,z) |
|
Comma separated x,y,z offsets of the data relative to the canonical tomogram in pixels. |
Rotation (x) |
|
– |
Tilt Offset |
|
– |
Affine Transformation Matrix |
|
– |
Tomogram Download Options¶
Individual entries in the Tomograms table can be downloaded using the Download button on the right side of each entry in the table. This button opens a dialog with tomogram selection in a drop down by name (whichever tomogram entry was chosen will be loaded by default) along with a dropdown to chose between MRC and OME-Zarr file format. On the next page of the dialog, the tomogram can be downloaded directly or if desired, code snippets and instructions are available in separate tabs for downloading the tomogram via cURL, AWS CLI, or the Portal API.
Annotations¶
Annotations are summarized in a table on Run Overview pages. Each annotation has an Annotation ID, which is assigned by the Portal and is subject to change in the rare case where the annotation data needs to be re-ingested in the Portal. Annotation IDs start with AN (e.g. AN-2480; note that only the numeric part is supported in the API). Each annotation labels exactly one type of object, such as ribosome or membrane, indicated by the Object Type column of the table. For every object, there is one type of annotation per entry in the table indicated in the Object Shape Type column. The options are Segmentation for semantic segmentation masks, Instance Segmentation for segmentation masks where each individual object is labeled with its own color, Point for point annotations, and Oriented Point for point annotations that have an associated rotation matrix. The method used for generating the annotation is displayed for each annotation with manual meaning the annotations were created by hand, automated meaning automated tools or algorithms without supervision were used, and hybrid meaning the annotations were generated using a combination of automated and manual methods.
Annotations also have an optional precision field, which is the percentage of true positives among the total number of positive predictions where a value of 100% means everything found is actually the object of interest, and a recall field, which is the percentage of true positives among the actual number of objects where a value of 100% meaning all objects of interest were found. The Precision and Recall fields can only be calculated by comparing with a ground truth annotation, so for many annotations on the Portal, this field is marked NA for not available.
Ground Truth Flag¶
Authors may also utilize the Ground Truth flag on entries in the annotation table. The Ground Truth flag indicates that this annotation is endorsed by the author for use as training or validation data for machine learning models.
Each annotation has its own metadata, which can be viewed using the info icon on the entry in the annotations table. These metadata are defined in the tables below including their mapping to attributes in the Portal API:
Annotation Overview
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Annotation ID |
|
Numeric identifier assigned by the Portal. |
Annotation Authors |
|
Authors of this annotation. |
Publication |
|
DOIs for publications that describe the dataset. |
Deposition Name |
|
|
Deposition ID |
|
The ID of the deposition this annotation is a part of. |
Deposition Date |
|
Date when an annotation set is initially received by the Data Portal. |
Release Date |
|
Date when annotation data is made public by the Data Portal. |
Last Modified Date |
|
Date when an annotation was last modified in the Data Portal. |
Alignment ID |
|
|
Method Type |
|
The method type for generating the annotation (e.g., manual, hybrid, automated). |
Annotation Method |
|
Describes how the annotation is made, e.g., Manual, crYoLO, Positive Unlabeled Learning, template matching. |
Annotation Software |
|
Software used for generating this annotation. |
Method Links |
|
Returns |
Annotation Object
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Object Name |
|
Name of the object being annotated, e.g., ribosome, nuclear pore complex, actin filament, membrane. |
Object ID |
|
Gene Ontology Cellular Component identifier or UniProtKB accession for the annotation object. |
Object Count |
|
Number of objects identified. |
Object Shape Type |
|
Description of whether this is a Point, OrientedPoint, or SegmentationMask file. |
Object State |
|
Additional information about the annotated object not captured by the gene ontology (e.g., open or closed state for molecules). |
Object Description |
|
Description of the annotated object, including additional information not covered by the Annotation object name and state. |
Annotation Confidence
Portal Metadata |
API Expression |
Definition |
|---|---|---|
Ground Truth Status |
|
Whether an annotation is considered ground truth, as determined by the annotation author. |
Ground Truth Used |
|
Annotation filename used as ground truth for precision and recall. |
Precision |
|
Percentage of annotation objects being true positive. |
Recall |
|
Percentage of true positives being annotated correctly. |
Visualizing Annotations with Tomograms in Neuroglancer¶
On the upper right hand side of Run Overview pages, the View Tomogram button opens Neuroglancer in a new tab with the “default” tomogram along with all its available annotations preloaded. The tooltip on the View Tomogram button specifies the ID of the “default” tomogram. By navigating to the Tomogram table using the tab above the Annotations table, you may also click the View Tomogram button for a specific tomogram entry to open it in Neuroglancer with applicable annotations preloaded. Check out our Neuroglancer Quickstart to learn more about navigating Neuroglancer.
There is no definitive rule for which annotations are open in the Neuroglancer canvases with a tomogram by default. However, all annotations can be opened in the canvas by clicking any annotation layers with strikethrough text in the list above the canvases. The annotations shown by default are manually chosen by the data curation team to display as many annotations as possible without overlap or occlusion. For example, when the cytoplasm is annotated as a whole, it would occlude other annotations, such as protein picks. When there is a ground truth and predicted annotation, the ground truth annotation is displayed by default. Authors contributing data can specify the desired default annotations during the submission process.
The CryoET Data Portal napari plugin can be used to visualize tomograms, annotations, and metadata. Refer to this documentation to learn about how to use the plugin and to this page to learn more about napari and CryoET Data Portal.
Annotation Download Options¶
Individual entries in the annotations table can be downloaded using the Download button on the right side of the table.
Instance Segmentations, Oriented Points, and Points all can be downloaded directly in the browser as Newline Delimited JSON (ndJSON) files, where each line in the file is its own JSON. The download dialog also has instructions for downloading using curl, Amazon Web Services Command Line Interface or the Portal API. In all cases, the JSON entries have a type field with instancePoint, orientedPoint, and point for Instance Segmentations, Oriented Points, and Points, respectively, and a location field with the x, y, z coordinates. For Instance Segmentations, there is also an instance_id to group points into geometric segmentation masks. For Oriented Points, there is also an xyz_rotation_matrix field with a 3x3 rotation matrix corresponding to each point.
Semantic segmentation masks can downloaded using Amazon Web Services Command Line Interface or the Portal API as MRC files or OME-Zarr directories. When downloading all annotations on a Run Overview page, both the MRC file and the OME-Zarr directory will be downloaded for each segmentation mask.