Open Science Resources
open science for biomedical research
This project has been retired and will not be updated after February 2026.
View the Project on GitHub chanzuckerberg/open-science
Search this site
Data overview
Topics in this section:
- Why publish data?
- Data management and documentation
- Data repositories
- Data reuse, ethics, and security
This section provides guidance on improving data management to ease the process of sharing and maximize your research impact, and also considers options for where to publish your data (e.g., selecting repositories).
Why publish data?
Curating and documenting data sufficiently for other researchers to use takes time and effort, and data management competes for attention with other high-priority research activities like generating data in the next experiment.
Given this pressure, the most straightforward answer to “Why share research data?” is that a variety of stakeholders require it, including:
- grant funders
- journal publishers
- institutional leadership (university, department, etc)
For example, the new NIH Policy on Data Management and Sharing comes into effect on January 25, 2023, and many projects are already adjusting their data management practices to accommodate these expectations.
Data sharing is becoming an increasingly frequent expectation because of the need for data to ensure reproducibility of published scientific research. In addition to improved robustness of scientific findings, data sharing can also benefit individual researchers (see Data sharing and how it can benefit your scientific career) by encouraging collaboration and reuse of existing data, both of which can accelerate the rate of scientific progress.
The content in this topic is framed around the idea of making data as FAIR as possible:
- Findable
- Accessible
- Interoperable
- Reusable
For more information on these guiding ideas, see The FAIR Guiding Principles for scientific data management and stewardship, an article describing the principles with examples.
Data management and documentation
This topic provides general guidance in best practices for organizing and documenting data, both within a single dataset and across data for an entire project. Good practices in data management and documentation are essential for efficient and timely data sharing, as well as improving workflows across the entire data life cycle.
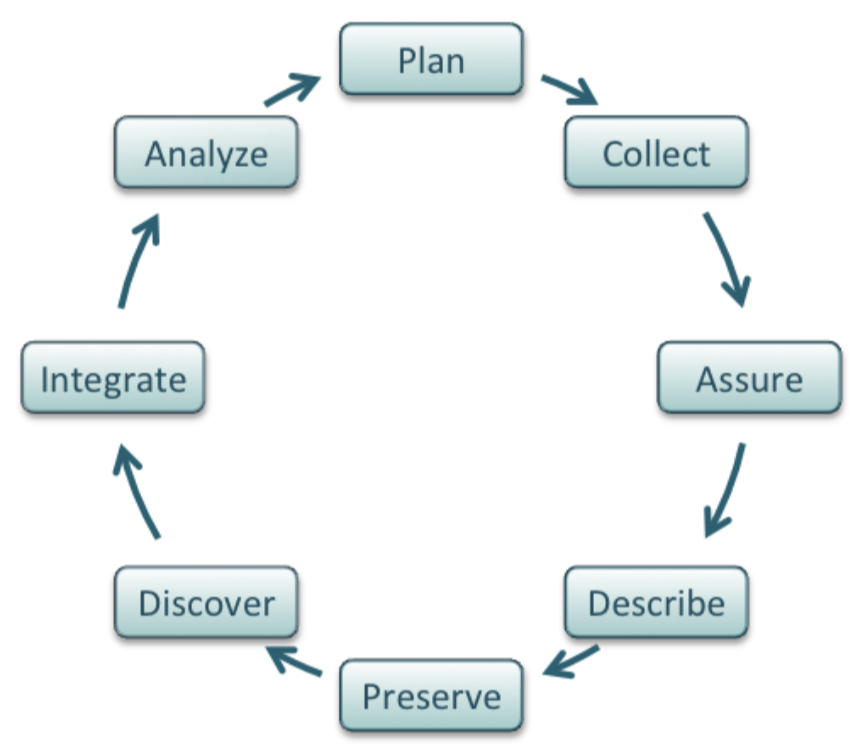
The DataONE Best Practices Primer, from which the image above is derived, describes guidelines for managing data throughout the life cycle of a project. Additional resources related to overall data management include:
- Ten Simple Rules for Creating a Good Data Management Plan
- Ten Simple Rules for the Care and Feeding of Scientific Data
- Research Data Management from Harvard University
Organizing data in spreadsheets
A great deal of scientific data is tabular in nature, with data organized into rows and columns, While spreadsheets make it easier for us to view and work with data, some common spreadsheet practices make it difficult to interpret and reuse the data later. These resources identify ways to improve the entry and organization of data in this format.
- Data Organization in Spreadsheets: Data Carpentry lesson demonstrating appropriate practices in data organization. Example data is ecological, but concepts can be applied to any data type.
- Tidy Data: paper by Hadley Wickham (developer of R’s tidyverse packages) that connects data organization practices with data manipulation for analysis
- Spreadsheet Help: collection of additional resources from California Digital Libraries
Organizing data across a project
Most research projects include multiple data files, representing different data types and structures. These data are subsequently filtered and manipulated during analysis, resulting in an even larger number of diverse files. The following resources provide a breadth of information for considering data management:
- Data Organization Best Practices: collection of resources from Harvard; includes practical solutions and considerations for all steps in a research project (planning, collecting, analyzing, storing, evaluating, sharing, and accessing)
- Ten Simple Rules for Digital Data Storage: high-level overview of planning and organization for large-scale datasets
These resources focus on projects including a computational computational component, and include approaches to support automation of data management:
- A Quick Guide to Organizing Computational Biology Projects: see File and directory organization
- Good Enough Practices in Scientific Computing: see Data management
Documenting data with metadata
Metadata refers to information and details about data. For more information about different types of metadata and it can be used in contexts ranging from social media to museums, please see Understanding Metadata: What is Metadata, and What is it For?: A Primer. The resources below will help you think about metadata from the context of scientific research, which focuses on providing information about the way data was collected and analyzed so that other researchers can understand and reuse it. Remember, though, that documenting your data is as important for yourself (and your collaborators) as for other scientists who may be interested in using it, and that documentation should occur throughout the research process– not only when it comes time to publish.
One of the most common tools for recording metadata is with a README, which is an extra file/document associated with data that describes important information about the dataset and how it was created. The following resources provide general information about READMEs, as well as additional guidance on how to document data in different contexts:
- Guide to writing “readme” style metadata from Cornell University
- Ten Simple Rules for Experiments’ Provenance
- Ten simple rules on how to write a standard operating procedure
- Ten simple rules for annotating sequencing experiments
Data repositories
Identifying what data to publish and where to deposit the data can be a daunting task. This section identifies types of data repositories and examples of repositories common in biomedical research.
Choosing data repositories
There are a variety of different types of data repositories appropriate for depositing and/or archiving biomedical data:
- discipline or topic-specific repositories, like the National Centralized Repository for Alzheimer’s Disease and Related Dementias)
- repositories for specific data types, like NCBI GEO and other federally funded data banks
- general data repositories, like institutional repositories and Dryad
For a more comprehensive exploration of biomedical data repositories, please see An overview of biomedical platforms for managing research data
The table below highlights data repositories that have been recommended by biomedical researchers for particular data types.
| Repository | Data types |
|---|---|
| CELLxGENE Data Portal | Single cell projects funded by the Single Cell Program, submissions handled by Lattice |
| Cell Image Library | image (still, video, z-stack, time series) |
| Brain Image Library | image (brain) |
| Image Data Resource | image (cell and tissue) |
| Data Dryad | any (also see section below) |
Publishing data with Dryad
Dryad is a repository that accepts research data of any type and format. Please view the Dryad topic page for more information and examples of data submissions.
Data reuse, ethics, and security
We publish data so that it will be acccessible to other researchers in the future. The following articles provide some context for associated issues with data reuse, including data ethics and privacy/security:
- Six tips for data sharing in the age of the coronavirus
- Ten simple rules for responsible big data research
- Ten Simple Rules to Enable Multi-site Collaborations through Data Sharing
- Ten Simple Rules for Developing Public Biological Databases
- Ethics Toolkit from the Human Cell Atlas
- The CARE Principles for Indigenous Data Governance